Project Objective
이 프로젝트에서는 트랜스포머 구조 자체에 집중해, 표준 트랜스포머와 이를 개선시킨 Recurrent & Evolved 트랜스포머를 직접 구현하고, 세 가지 자연어 생성과제(기계번역, 대화생성, 문서요약)에서 각 모델 구조의 성능을 검증합니다.
1. Introduction
- Description
- Objective
- Standard Transformer, Recurrent Transformer, Evolved Trasnformer 구현을 통한, Transformer 모델링 다양화 방식에 대한 깊은 이해
- Standard Transformer, Recurrent Transformer, Evolved Trasnformer 모델의 자연어 생성 능력 비교 검증
Transformer는 Attention을 활용한 뛰어난 성능을 바탕으로 다양한 분야의 딥러닝 모델의 표준이 되었습니다. 하지만 Standard Transformer는 여전히 개선될 여지가 많이 남아 있습니다. Transformer 모델 자체의 개선을 위한 연구는 상대적으로 부족하며, Transformer 변주 모델들에 대한 자연어 생성과제에서의 비교연구는 부재합니다. 이 프로젝트에서는 앞서 언급한 문제를 직접 해결하고, Transformer의 모델 디자인적인 변주를 통해 어떠한 성능 변화를 이끌어낼수 있는지 직접 확인해봅니다.
2. Background
- Transformer
트랜스포머는 Attention Is All You Need 논문에서 소개된 모델 구조로, 어텐션 메커니즘을 활용해 장거리 종속성을 효과적으로 다루고 병렬 처리 학습이 가능하다는 장점을 지닙니다. 인코더와 디코더로 이루어져 텍스트 처리에 적합하며, 특히 셀프 어텐션과 포지션 임베딩을 통해 문장의 의미와 순서 정보를 효과적으로 학습해 자연어 처리에서 혁신적인 성과를 보입니다. 트랜스포머 이전의 헤게모니 모델 디자인이었던, 순환 신경망 대비 높은 성능과 학습 효율성을 제공하며, 대규모 데이터셋에서 활용되는 강력한 모델이라고 할 수 있습니다.
- Biased Research
- 트랜스포머의 도래 이후, 대부분의 연구들은 트랜스포머 구조를 기반으로한 사전학습 방법론에 집중하고 있음
- 디코더는 인코더의 출력을 기반으로 출력 시퀀스를 생성. 각 디코더 레이어는 다중 헤드 어텐션을 사용하여 인코더의 출력과 현재까지의 디코더 입력에 대한 어텐션을 계산하고, 피드포워드 신경망을 통해 출력을 생성. 잔여 연결과 층 정규화는 안정성을 제공하며 디코딩 과정을 안정화.
- 인코더와 디코더는 각각의 레이어를 통해 상호작용하며, 어텐션 메커니즘을 활용해 입력 문장의 문맥 정보를 고려하고 출력 문장을 생성. 트랜스포머의 인코더-디코더 구조는 기존의 번역 모델보다 효과적인 학습과 예측을 가능케 함.
3. Architecture
- Recurrent Transformer
- 트랜스포머의 인코더는 입력 시퀀스의 단어들을 임베딩하고, 다중 헤드 어텐션과 피드포워드 신경망을 통해 정보를 추상화. 각 인코더 레이어는 잔여 연결과 층 정규화를 활용하여 안정성을 유지하며, 입력 문장의 특징을 계층적으로 추출
- 디코더는 인코더의 출력을 기반으로 출력 시퀀스를 생성. 각 디코더 레이어는 다중 헤드 어텐션을 사용하여 인코더의 출력과 현재까지의 디코더 입력에 대한 어텐션을 계산하고, 피드포워드 신경망을 통해 출력을 생성. 잔여 연결과 층 정규화는 안정성을 제공하며 디코딩 과정을 안정화.
- 인코더와 디코더는 각각의 레이어를 통해 상호작용하며, 어텐션 메커니즘을 활용해 입력 문장의 문맥 정보를 고려하고 출력 문장을 생성. 트랜스포머의 인코더-디코더 구조는 기존의 번역 모델보다 효과적인 학습과 예측을 가능케 함.
- Evolved Transformer
- 트랜스포머의 핵심 구성 요소로, 여러 어텐션 헤드를 병렬로 활용하여 다양한 어텐션 가중치를 학습
- 각 헤드는 서로 다른 관점에서 정보를 추출하며, 그 결과를 결합하여 모델이 다양한 특징을 효과적으로 학습하도록 유도
- Attention Score 산출을 위해 Scaled Dot Attention 방식을 사용
- 모델의 복잡성으로 인해, 과적합 문제가 발생
- 과적합 방지를 위해 데이터 증강, 하이퍼 파라미터 조정을 했으나, 과적합 방지 실패
- Recurrent Hybrid Transformer
- 트랜스포머의 인코더는 입력 시퀀스의 단어들을 임베딩하고, 다중 헤드 어텐션과 피드포워드 신경망을 통해 정보를 추상화. 각 인코더 레이어는 잔여 연결과 층 정규화를 활용하여 안정성을 유지하며, 입력 문장의 특징을 계층적으로 추출
- 디코더는 인코더의 출력을 기반으로 출력 시퀀스를 생성. 각 디코더 레이어는 다중 헤드 어텐션을 사용하여 인코더의 출력과 현재까지의 디코더 입력에 대한 어텐션을 계산하고, 피드포워드 신경망을 통해 출력을 생성. 잔여 연결과 층 정규화는 안정성을 제공하며 디코딩 과정을 안정화.
- 인코더와 디코더는 각각의 레이어를 통해 상호작용하며, 어텐션 메커니즘을 활용해 입력 문장의 문맥 정보를 고려하고 출력 문장을 생성. 트랜스포머의 인코더-디코더 구조는 기존의 번역 모델보다 효과적인 학습과 예측을 가능케 함.
- Evolved Hybrid Transformer
- 트랜스포머의 핵심 구성 요소로, 여러 어텐션 헤드를 병렬로 활용하여 다양한 어텐션 가중치를 학습
- 각 헤드는 서로 다른 관점에서 정보를 추출하며, 그 결과를 결합하여 모델이 다양한 특징을 효과적으로 학습하도록 유도
- Attention Score 산출을 위해 Scaled Dot Attention 방식을 사용
4. Experimental Setup
- Data Setup
- Translation Task: WMT'14 En-De
- Dialogue Task: Daily Dialogue
- Summarization Task: CNN Daily
- Tokenizer: BPE Tokenizer
- Train Data Volumn: 50,000
- Valid Data Volumn: 5,000
- Test Data Volumn: 100
- Vocab Size: 15,000
- Training Setup
- Hardware: Google Colab A100 GPU
- Num Epochs: 10
- Batch Size: 32
- Learning Rate: 5e-4
- Optimizer: AdamW
- LR Scheduler: ReduceLROnPlateau
- Apply Mixed Precision Training: True
- Gradient Accumulation Steps: 4
- Model Setup
- Input Dim: 30,000
- Output Dim: 30,000
- Embedding Dim: 256
- Hidden Dim: 256
- PFF Dim: 512
- N Layers: 4
| Model Type | Model Params | Model Size |
|---|---|---|
| Standard | 28,341,552 | 109.114 MB |
| Recurrent | 24,388,912 | 94.036 MB |
| Evolved | 29,292,080 | 112.740 MB |
| Recurrent Hybrid | 26,760,752 | 103.084 MB |
| Evolved Hybrid | 28,680,496 | 110.407 MB |
5. Result
- Machine Translation
- Dialogue Generation
- Text Summarization
- Result Analysis
| Model Type | Eval Score | Epoch Time | Avg GPU | Max GPU |
|---|---|---|---|---|
| Standard | 12.84 | 0m 59s | 0.36GB | 1.56GB |
| Recurrent | 14.46 | 0m 57s | 0.31GB | 1.50GB |
| Evolved | 0.00 | 1m 07s | 0.36GB | 1.58GB |
| Recurrent Hybrid | 11.59 | 0m 58s | 0.34GB | 1.54GB |
| Evolved Hybrid | 11.92 | 1m 04s | 0.36GB | 1.58GB |
| Model Type | Eval Score | Epoch Time | Avg GPU | Max GPU |
|---|---|---|---|---|
| Standard | 3.40 | 0m 57s | 0.36GB | 1.48GB |
| Recurrent | 4.15 | 0m 56s | 0.32GB | 1.40GB |
| Evolved | 0.00 | 1m 07s | 0.37GB | 1.49GB |
| Recurrent Hybrid | 1.62 | 0m 57s | 0.35GB | 1.43GB |
| Evolved Hybrid | 0.44 | 1m 00s | 0.37GB | 1.46GB |
| Model Type | Eval Score | Epoch Time | Avg GPU | Max GPU |
|---|---|---|---|---|
| Standard | 6.08 | 3m 20s | 0.38GB | 2.89GB |
| Recurrent | 5.34 | 3m 20s | 0.34GB | 2.88GB |
| Evolved | 0.00 | 3m 10s | 0.39GB | 2.93GB |
| Recurrent Hybrid | 5.57 | 3m 21s | 0.36GB | 2.88GB |
| Evolved Hybrid | 9.34 | 3m 13s | 0.38GB | 3.24GB |
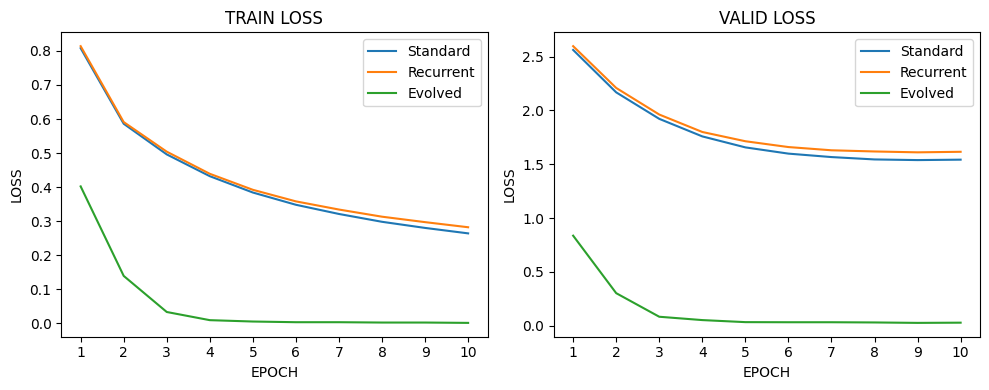
위의 결과를 보면, Evolved Transformer의 학습이 제대로 진행되지 않은 것을 확인할 수 있습니다. Training Log를 확인해본 결과, Loss는 과도하게 잘 줄어들고 있지만, 복잡한 구조탓에 하이퍼파라미터에 민감하게 반응한 것으로 판단됩니다. 의외로 Recurrent Transformer가 기계번역에서 가장 좋은 성능을 낸것도 놀랍습니다. 이는 모델적 특성과 데이터의 특성이 잘 맞아 좋은 결과가 반영된 것으로 판단할 수 있습니다. 추가적으로 복잡한 연산탓에 효율성이 낮을것이라고 예상했던 Evolved Transformer가 좋은 효율성을 보여준 점도 놀랍습니다.
6. Conclusion
이 프로젝트에서는 세가지 Transformer를 직접 구현하고 세 가지 자연어 생성 과제에서 직접 성능비교까지 해봤습니다. Evoled Transformer가 가장 좋은 성능을 보일 것이라는 초기의 예상과 달리, 복잡한 모델 구조에서 기인한 하이퍼 파라미터에 민감도가 높아 좋지 않은 성능을 보인 것으로 판단되며, Recurrent Transformer는 기계번역이라는 한 가지 과제에서만 좋은 성적을 기록했습니다. 일련의 실험을 통헤 Standard Transformer의 안정성을 다시 한번 확인할 수 있었고, Transformer의 복잡성에 기인한 더 깊은 추가 연구가 필요하다는 것을 느끼게 되었습니다.