Project Objective
이 프로젝트에서는 사전학습된 언어 인코더 모델을 Seq2Seq 아키텍처에서 활용하기 위한 7개의 모델 구조를 제시하고, 각 모델의 자연어 생성 능력을 검증합니다. 변인이 되는 세 가지 모델 구조는 PLE와의 결합 방식에 따라 Simple, Parallel, Sequential 모델이라고 명명하며, Parallel, Sequential 모델은 Encoder, Decoder 그리고 Encoder & Decoder 세가지 방식으로 적용하며 PLE의 결합 시너지를 면밀하게 살펴봅니다.
1. Introduction
- Description
- Objective
- 사전학습 인코더 모델을 Transformer Seq2Seq에서 활용하기 위한 방법론 별 자연어 생성 능력 비교
- 추후 다양한 사전학습 모델 사용을 통한 다양한 연구로의 발전 가능성 제고
최근 BERT를 필두로 한, 다양한 사전학습 인코더 모델들이 다양한 자연어 처리 영역에서 좋은 성과를 보이고 있습니다. 사전학습 인코더 모델의 경우, 그 적용 범위가 더 넓은 덕에 더 다양하게 연구되어지고 있는 반면, 상대적으로 사전학습 Seq2Seq 모델의 수는 적습니다. 때문에 이 프로젝트에서는 다양한 사전학습 인코더 모델을 Transformer Seq2Seq 구조안에서 사용하기 위한 세 가지 구조 방법론 안에서 적용범위에 차별을 두며 총 7개의 모델을 구현하고, 각 모델의 성능을 직접 확인합니다.
실험 모델의 Backbone 모델은 Transformer이며, 사전학습 인코더 모델로는 하드웨어의 한계를 고려해 비교적 가벼운 AlBERT 사전학습 모델을 선정했습니다. 가장 간단한 방식의 사전학습 인코더의 적용 모델을 Simple Model, 그리고 기본 Transformer 골조 안에서 사전학습 모델의 결과값을 적절히 혼합해서 사용하기 위한 모델구조를 Fusion Model이라고 명명합니다. 그리고 각 모델의 성능은 기계번역, 대화생성, 문서요약이라는 세 가지 자연어 생성 과제에서 진행합니다. 모델 구조를 제외한 모든 실험 변인은 동일하게 적용합니다.
2. Background
- Pretrained Encoder Model
- 트랜스포머의 인코더는 입력 시퀀스의 단어들을 임베딩하고, 다중 헤드 어텐션과 피드포워드 신경망을 통해 정보를 추상화. 각 인코더 레이어는 잔여 연결과 층 정규화를 활용하여 안정성을 유지하며, 입력 문장의 특징을 계층적으로 추출
- 디코더는 인코더의 출력을 기반으로 출력 시퀀스를 생성. 각 디코더 레이어는 다중 헤드 어텐션을 사용하여 인코더의 출력과 현재까지의 디코더 입력에 대한 어텐션을 계산하고, 피드포워드 신경망을 통해 출력을 생성. 잔여 연결과 층 정규화는 안정성을 제공하며 디코딩 과정을 안정화.
- 인코더와 디코더는 각각의 레이어를 통해 상호작용하며, 어텐션 메커니즘을 활용해 입력 문장의 문맥 정보를 고려하고 출력 문장을 생성. 트랜스포머의 인코더-디코더 구조는 기존의 번역 모델보다 효과적인 학습과 예측을 가능케 함.
- Lack of Pretrained Seq2Seq Model
- 트랜스포머의 인코더는 입력 시퀀스의 단어들을 임베딩하고, 다중 헤드 어텐션과 피드포워드 신경망을 통해 정보를 추상화. 각 인코더 레이어는 잔여 연결과 층 정규화를 활용하여 안정성을 유지하며, 입력 문장의 특징을 계층적으로 추출
- 디코더는 인코더의 출력을 기반으로 출력 시퀀스를 생성. 각 디코더 레이어는 다중 헤드 어텐션을 사용하여 인코더의 출력과 현재까지의 디코더 입력에 대한 어텐션을 계산하고, 피드포워드 신경망을 통해 출력을 생성. 잔여 연결과 층 정규화는 안정성을 제공하며 디코딩 과정을 안정화.
- 인코더와 디코더는 각각의 레이어를 통해 상호작용하며, 어텐션 메커니즘을 활용해 입력 문장의 문맥 정보를 고려하고 출력 문장을 생성. 트랜스포머의 인코더-디코더 구조는 기존의 번역 모델보다 효과적인 학습과 예측을 가능케 함.
- Transformer Fusion
- 트랜스포머의 인코더는 입력 시퀀스의 단어들을 임베딩하고, 다중 헤드 어텐션과 피드포워드 신경망을 통해 정보를 추상화. 각 인코더 레이어는 잔여 연결과 층 정규화를 활용하여 안정성을 유지하며, 입력 문장의 특징을 계층적으로 추출
- 디코더는 인코더의 출력을 기반으로 출력 시퀀스를 생성. 각 디코더 레이어는 다중 헤드 어텐션을 사용하여 인코더의 출력과 현재까지의 디코더 입력에 대한 어텐션을 계산하고, 피드포워드 신경망을 통해 출력을 생성. 잔여 연결과 층 정규화는 안정성을 제공하며 디코딩 과정을 안정화.
- 인코더와 디코더는 각각의 레이어를 통해 상호작용하며, 어텐션 메커니즘을 활용해 입력 문장의 문맥 정보를 고려하고 출력 문장을 생성. 트랜스포머의 인코더-디코더 구조는 기존의 번역 모델보다 효과적인 학습과 예측을 가능케 함.
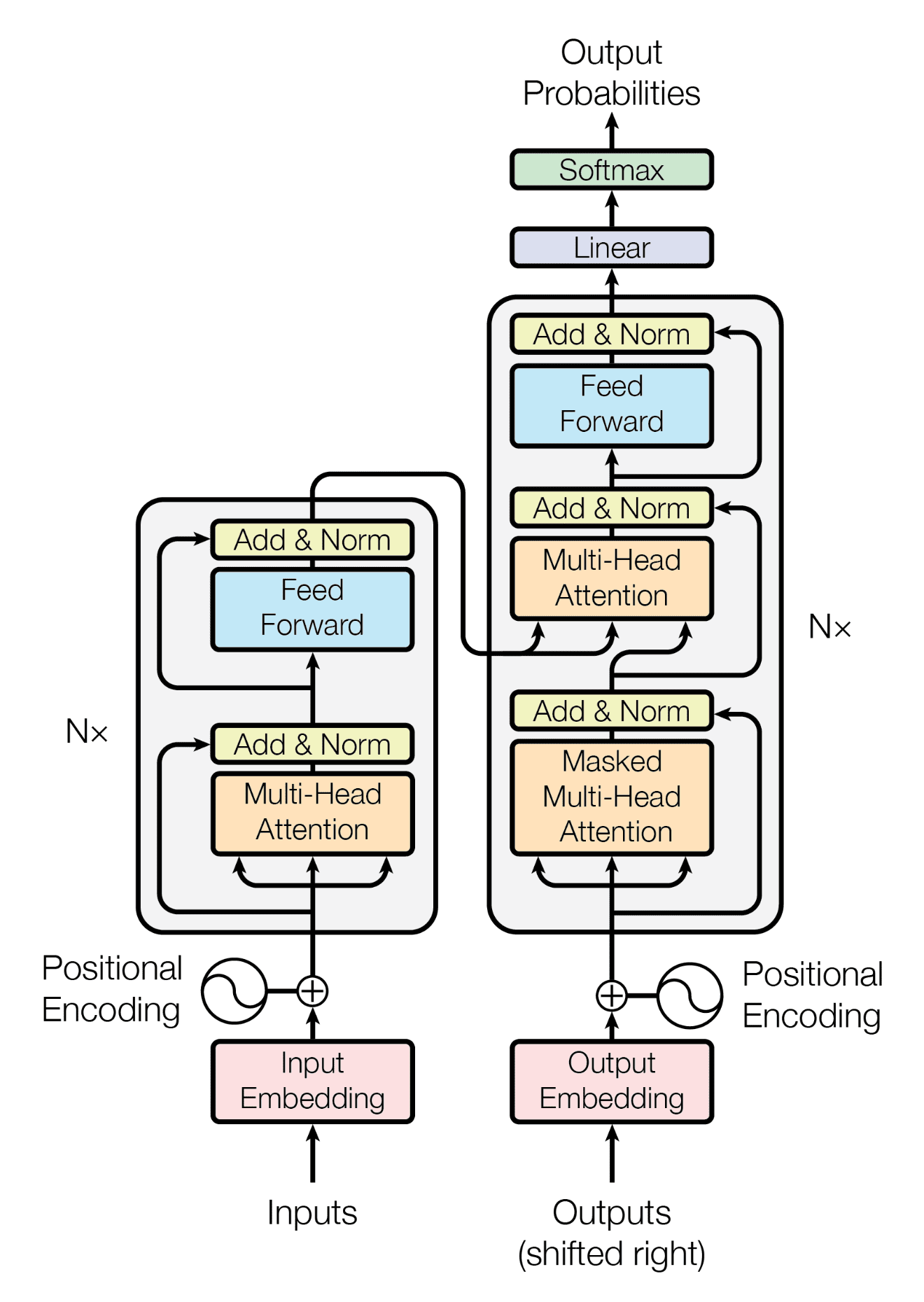
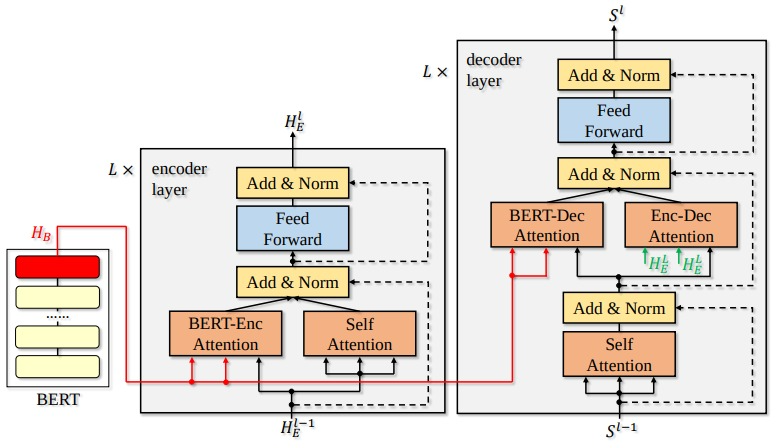
3. Architecture
- Simple Fusion Model
- 표준 트랜스포머의 인코더를 PLE로 대체한 모델 구조
- 가장 직관적이고, 단순한 Fusion방식으로, 구현이 간단하다는 장점이 있음
- 인코더를 제외한 모든 모델 구조는 표준 트랜스포머와 동일
- Parallel Fusion Model
- "Incorporating BERT into Neural Machine Translation" 논문에서 제시한 모델 구조
- PLE를 인코더로만 사용하는것이 아니라, 인코딩과 디코딩 과정에 추가적인 정보전달을 위한 모델로 활용
- Sequential Fusion Model
- 어텐션이 순차적으로 이어지도록 유도한 모델 구조
- 단순한 덧셈 연산으로는 서로 상이한 기저차원의 값들의 요소들을 제대로 반영하기 어려울것 같다는 가정에서 출발한 모델
4. Experimental Setup
- Data Setup
- Translation Task: WMT'14 En-De
- Dialogue Task: Daily Dialogue
- Summarization Task: CNN Daily
- Tokenizer: AlBERT Pretrained Tokenizer
- Train Data Volumn: 50,000
- Valid Data Volumn: 5,000
- Test Data Volumn: 100
- Vocab Size: 15,000
- Training Setup
- Hardware: Google Colab TPU
- Num Epochs: 10
- Batch Size: 32
- Optimizer: AdamW
- Learning Rate: 5e-4
- Learning Rate for PLE: 5e-5
- LR Scheduler: ReduceLROnPlateau
- Gradient Accumulation Steps: 4
- Model Setup
- PLE Architecture: AlBERT
- Input & Output Dim: 30,000
- Hidden Dim: 256
- Pff Dim: 512
- Num Layers: 3
- Num Heads: 8
- Model Size
| Model Type | Total Params | Trainable Params | Model Size |
|---|---|---|---|
| Simple Model | 22,192,688 | 10,509,104 | 84.666 MB |
| Parallel Model | 25,193,264 | 13,509,680 | 96.112 MB |
| Sequential Model | 25,199,408 | 13,515,824 | 96.136 MB |
5. Result
- Machine Translation
- Dialogue Generation
- Text Summarization
- Ablation Study
- Result Analysis
| Model Type | Eval Score | Epoch Time | Avg GPU | Max GPU |
|---|---|---|---|---|
| Transformer | 13.72 | 53s | 0.20GB | 0.95GB |
| Simple Fusion | 9.58 | 2m 13s | 0.22GB | 1.72GB |
| Parallel Fusion | 9.58 | 2m 31s | 0.26GB | 1.92GB |
| Sequential Fusion | 9.57 | 2m 32s | 0.26GB | 1.94GB |
| Model Type | Eval Score | Epoch Time | Avg GPU | Max GPU |
|---|---|---|---|---|
| Transformer | 1.34 | 42s | 0.20GB | 0.85GB |
| Simple Fusion | 6.55 | 1m 38s | 0.21GB | 1.25GB |
| Parallel Fusion | 6.59 | 1m 54s | 0.24GB | 1.42GB |
| Sequential Fusion | 6.55 | 1m 53s | 0.24GB | 1.45GB |
| Model Type | Eval Score | Epoch Time | Avg GPU | Max GPU |
|---|---|---|---|---|
| Transformer | 1.34 | 3m 42s | 0.20GB | 0.85GB |
| Simple Fusion | 7.33 | 18m 47s | 0.22GB | 3.01GB |
| Parallel Fusion | 7.36 | 22m 9s | 0.25GB | 4.01GB |
| Sequential Fusion | 7.30 | 22m 30s | 0.25GB | 4.01GB |
| Model Type | Translation Score | Epoch Time | Avg GPU | Max GPU |
|---|---|---|---|---|
| Parallel Encoder Fusion | 9.61 | 2m 27s | 0.25GB | 1.87GB |
| Parallel Decoder Fusion | 9.60 | 2m 29s | 0.25GB | 1.89GB |
| Sequential Encoder Fusion | 9.62 | 2m 26s | 0.25GB | 1.88GB |
| Sequential Decoder Fusion | 9.58 | 2m 27s | 0.25GB | 1.90GB |
| Model Type | Dialogue Score | Epoch Time | Avg GPU | Max GPU |
|---|---|---|---|---|
| Parallel Encoder Fusion | 6.50 | 1m 51s | 0.23GB | 1.39GB |
| Parallel Decoder Fusion | 6.57 | 1m 48s | 0.23GB | 1.40GB |
| Sequential Encoder Fusion | 6.56 | 1m 49s | 0.23GB | 1.40GB |
| Sequential Decoder Fusion | 6.54 | 1m 50s | 0.23GB | 1.41GB |
Simple Model이 Fusion Model에 비해 좋은 성능을 보입니다. 하나 특이한 결과는 최대 GPU 사용량에서 더 크고, 연산과정이 복잡한 Fusion모델의 효율성이 더 높게 나온다는 점입니다. 이를 이전 실험에서 Transformer의 성능과 비교해보
6. Conclusion
- Transformer의 틀 안에서 사전학습 언어 인코더 모델을 활용할 수 있는 아키텍처 구현
- 세 가지 순환 신경망의 성능 비교 검증
가장
LSTM은 게이트 메커니즘을 통해 장기 의존성 문제를 해결하는 데 강점을 보입니다. 복잡한 문맥을 학습하고 기억하는 데 탁월하며, 긴 시퀀스 데이터에서 뛰어난 성능을 발휘할 수 있습니다. 하지만 LSTM은 더 많은 파라미터를 가지고 있어서 더 많은 데이터와 계산 리소스가 필요할 수 있습니다.