Project Objective
이 프로젝트에서는 RNN 모델에서 주로 사용되던 Scheduled Sampling을 Transformer에서 활용하기 위한 방법론을 직접 구현하고, Sampling Ratio에 따른 성능 변화를 직접 확인합니다. 기존의 Scheduled Sampling은 학습 과정에서 생성을 동반하기 때문에 Transformer에서 사용하기 적합하지 않은 방법론입니다. 하지만, 이를 해결한 Scheduled Sampling for Transformers 논문의 방법론을 활용해 실험을 진행합니다. 실험의 모델 구조는 Transformer이며, 기계번역, 대화생성, 문서요약이라는 세 가지 과제를 선정해 자연어 생성 능력을 평가합니다.
1. Introduction
- Description
- Objective
- Scheduled Sampling for Transformers 구현
- Sampling Ratio 별 자연어 생성 능력의 변화 확인
- Scheduled Sampling의 Exposure Bias 완화 기능 확인
자연어 생성을 위한 Sequence to Sequence 모델 구조에서는 Exposure Bias라는 문제점이 빈번하게 발생합니다. 학습과정과 실제 추론과정 사이 괴리에서 기인하는 이 문제를 해결하기 위한 다양한 방법론이 존재하며, 그 방법론 중 하나가 바로 Scheduled Sampling. 하지만 Scheduled Sampling은 학습과정 안에서 생성을 동반하기 때문에 Transformer에 사용하기 적합하지 않습니다. 하지만 이런 문제를 해결하며 새로운 방법론을 제시한 Scheduled Sampling for Transformers라는 논문이 있었습니다. 이 논문에서 아이디어를 얻어, 이 프로젝트에서는 다양한 Sampling Ratio 별 Scheduled Sampling의 효용성을 세가지 자연어 과제에서 검증해봅니다.
2. Background
- Exposure Bias
Exposure bias은 sequence-to-sequence 모델에서 발생하는 현상을 의미하며, 모델이 훈련과 테스트 단계에서 서로 다른 분포에서 샘플을 처리할 때 발생합니다. 일반적으로 훈련 단계에서는 모델이 실제 훈련 데이터를 사용하여 다음 토큰을 예측합니다. 반면 테스트 단계에서는 이전 토큰을 모델이 직접 생성한 경우를 기반으로 예측을 수행합니다. 이로 인해 훈련 단계에서 모델은 실제 데이터에서 본 경험을 통해 예측을 수행하고, 테스트 단계에서는 자체 생성 결과를 사용하여 예측하게 됩니다.
Exposure bias는 이러한 차이 때문에 발생하는데, 모델이 훈련 데이터에서 봤던 내용을 기반으로 하는 데서 벗어나 테스트 데이터에 적응하는 데 어려움을 겪을 수 있습니다. 특히 모델이 훈련 데이터에 존재하지 않는 토큰이나 문법적인 다양성이 테스트 데이터에서 나타날 때 이 문제가 더 복잡해집니다. - Scheduled Sampling
Scheduled sampling은 sequence-to-sequence 모델에서 사용되는 훈련 기술 중 하나입니다. 주로 기계 번역 및 자연어 처리 작업에서 적용됩니다. Sequence-to-sequence 모델은 주로 인코더-디코더 구조로 이루어져 있습니다. 인코더는 입력 시퀀스를 임베딩하고, 디코더는 이를 기반으로 출력 시퀀스를 생성합니다. 훈련하는 동안, 디코더는 이전 스텝에서 생성한 토큰을 사용하여 다음 토큰을 예측합니다. 그러나 테스트할 때는 디코더가 이전에 생성한 토큰을 실제로 사용하게 됩니다.
Scheduled sampling은 훈련 중에 디코더에게 훈련 데이터에서 추출한 실제 이전 토큰 대신 모델이 이전 스텝에서 생성한 토큰을 입력으로 사용하도록 하는 방법입니다. 이를 통해 모델을 더 일반적으로 훈련시킬 수 있으며, 더 나은 일반화 성능을 얻을 수 있습니다.
주요 아이디어는 훈련 중에는 모델이 자신의 예측을 계속 사용하면서 점진적으로 실제 데이터를 노출시키는 것입니다. 처음에는 모델이 생성한 토큰을 많이 사용하다가, 훈련이 진행됨에 따라 실제 데이터를 더 많이 사용하게 됩니다. 이러한 스케줄은 훈련 초기에는 높은 확률로 모델이 생성한 토큰을 사용하다가, 훈련이 진행됨에 따라 이 확률을 감소시키는 방식으로 조절할 수 있습니다. Scheduled sampling을 통해 모델은 테스트할 때와 유사한 상황에서 훈련되므로, 더 나은 일반화 능력을 갖게 될 수 있습니다.
3. Scheduled Sampling for Transformers
- Concept
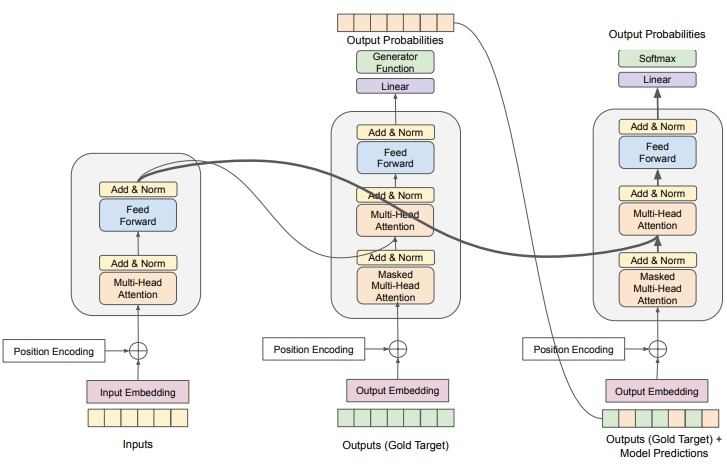
Scheduled Sampling을 Transformer에서 구현하기 위해, 위 그림과 같이 디코딩 과정을 두번 진행합니다. 원래의 Scheduling Sampling은 Auto Regressive하게 시퀀스를 생성하고, 매 Time Step마다 Scheduling Sampling을 사용할지 말지 선택합니다. 하지만 Transformer 모델의 특성 상, 생성 과정에 효율성이 매우 하락합니다. 효율성 하락이라는 이슈를 해결하고, 가장 Transformer 적인 연산안에서 Scheduled Sampling을 사용하기 위해, 위와 같은 방식을 사용합니다.
학습 시 디코딩 과정을 자세히 살펴보자면, 우선 첫번째 디코딩에서는 일반적인 Transformer의 방식과 동일하게 Self Attention과 Encoder-Decoder Attention을 거쳐 Logit 값을 반환합니다. 이때 반환된 Logit값은 Token으로 반환되어 Scheduled Sampling이 진행됩니다. 이후 Sampled Input을 다시금 디코더의 입력으로 주어 두번째 디코딩이 진행됩니다. - Code Implementation
class Transformer(nn.Module): def __init__(self, config): super(Transformer, self).__init__() self.pad_id = config.pad_id self.bos_id = config.bos_id self.device = config.device self.vocab_size = config.vocab_size self.sampling_ratio = config.sampling_ratio self.do_sample = self.sampling_ratio > 0 self.encoder = Encoder(config) self.decoder = Decoder(config) self.generator = nn.Linear(config.hidden_dim, config.vocab_size) self.criterion = nn.CrossEntropyLoss() self.out = namedtuple('Out', 'logit loss') def pad_mask(self, x): return x == self.pad_id def dec_mask(self, x): sz = x.size(1) mask = torch.triu(torch.full((sz, sz), float('-inf')), diagonal=1) return mask.to(self.device) def sampling(self, logit, y): bs, seq_len = y.shape pred = logit.argmax(dim=-1) sampled = torch.empty(bs, seq_len, self.vocab_size, dtype=torch.long) sampled = sampled.fill_(self.pad_id) sampled[:, 0] = self.bos_id for t in range(1, seq_len): if random.random() < self.sampling_ratio: sampled[:, t] = y[:, t] else: sampled[:, t] = pred[:, t] return sampled.to(self.device) @staticmethod def shift_y(x): return x[:, :-1], x[:, 1:] def forward(self, x, y): y, label = self.shift_y(y) #Masking e_mask = self.pad_mask(x) d_mask = self.dec_mask(y) #Actual Processing memory = self.encoder(x, e_mask) dec_out = self.decoder(y, memory, e_mask, d_mask) logit = self.generator(dec_out) if self.do_sample: y = self.sampling(logit, y) d_mask = self.dec_mask(y) dec_out = self.decoder(y, memory, e_mask, d_mask) logit = self.generator(dec_out) #Getting Outputs self.out.logit = logit self.out.loss = self.criterion( logit.contiguous().view(-1, self.vocab_size), label.contiguous().view(-1) ) return self.out
4. Experimental Setup
- Data Setup
- Translation Task: WMT'14 En-De
- Dialogue Task: Daily Dialogue
- Summarization Task: CNN Daily Mail
- Tokenizer: BPE Tokenizer
- Vocab Size: 15,000
- Train Data Volumn: 50,000
- Valid Data Volumn: 5,000
- Test Data Volumn: 100
- Model Setup
- Architecture: Transformer
- Input Dim: 15,000
- Output Dim: 15,000
- Embedding Dim: 512
- Hidden Dim: 512
- Model Params: 15,488,664
- Model Size: 60.085 MB
- Training Setup
- Num Epochs: 10
- Batch Size: 32
- Learning Rate: 5e-4
- LR Scheduler: ReduceLROnPlateau
- Optimizer: AdamW
- Apply Gradient Checkpoint: True
- Gradient Accumulation Steps: 4
- Early Stop Patient: 3
5. Result
- Machine Translation
- Dialogue Generation
- Text Summarization
- Result Analysis
| Sampling Ratio | Score | Epoch Time | Avg GPU | Max GPU |
|---|---|---|---|---|
| 0.0 | 12.99 | 0m 44s | 0.20GB | 0.95GB |
| 0.1 | 2.11 | 1m 00s | 0.20GB | 0.95GB |
| 0.3 | 7.34 | 1m 00s | 0.20GB | 0.95GB |
| 0.5 | 6.94 | 1m 00s | 0.20GB | 0.95GB |
| Sampling Ratio | Score | Epoch Time | Avg GPU | Max GPU |
|---|---|---|---|---|
| 0.0 | 2.03 | 0m 43s | 0.20GB | 0.85GB |
| 0.1 | 2.31 | 0m 59s | 0.20GB | 0.85GB |
| 0.3 | 2.34 | 0m 59s | 0.20GB | 0.85GB |
| 0.5 | 0.82 | 0m 59s | 0.20GB | 0.85GB |
| Sampling Ratio | Score | Epoch Time | Avg GPU | Max GPU |
|---|---|---|---|---|
| 0.0 | 7.60 | 2m 44s | 0.21GB | 2.78GB |
| 0.1 | 2.95 | 3m 8s | 0.21GB | 2.78GB |
| 0.3 | 4.10 | 3m 8s | 0.21GB | 2.78GB |
| 0.5 | 5.39 | 3m 8s | 0.21GB | 2.78GB |
Scheduled Sampling이 대화 생성에서는 긍정적인 영향을 끼치긴 했지만, 미미한 수준에 그칠 뿐이며, 나머지 과제에서는 모두 성능과 효율성 모두에 악영향을 미쳤습니다. 이를 통해 Scheduled Sampling이 Transformer에서는 맞지 않는 학습 방식임을 알 수 있습니다.
6. Conclusion
이 프로젝트에서는 Scheduled Sampling for Transformers 논문에서 소개한 내용을 토대로, 코드를 구성하고, 세가지 자연어 생성 과제에서 그 성능을 검증해봤습니다. 결과적으로는 Scheduled Sampling for Transformers 방법론이 Transformer에는 맞지 않는 학습 방식이라는 것을 확인했습니다. Exposure Bias라는 문제점을 완화하기 위한 다양한 방법론 중 하나를 직접 검증해보며, 추후 Exposure Bias 완화를 위한 연구에 참고점으로 삼을 수 있을 것 같습니다.