Project Objective
이 프로젝트는 트랜스포머 구조를 활용해 문서 요약이라는 긴 시퀀스를 효율적으로 해결하기 위한 방법론을 심층적으로 검증합니다. 총 4개의 방법론을 제시하며, 모든 방법론은 시퀀스 길이에 관한 주요 정보가 Low Rank에 존재한다는 주장에 기반했던 Linformer 연구를 기반으로 합니다.
1. Introduction
- Description
- Objective
- Linformer에서 제시하는 Low Rank Projection Sequence Length 방법론의 효용성 탐색
- Linformer의 방법론이 적용되는 모델 구조적 변인에 따른 결과 분석
자연어 생성을 위한 Sequence to Sequence 모델 구조에서는 Exposure Bias라는 문제점이 빈번하게 발생합니다. 학습과정과 실제 추론과정 사이 괴리에서 기인하는 이 문제를 해결하기 위한 다양한 방법론이 존재하며, 그 방법론 중 하나가 바로 Scheduled Sampling. 하지만 Scheduled Sampling은 학습과정 안에서 생성을 동반하기 때문에 Transformer에 사용하기 적합하지 않습니다. 하지만 이런 문제를 해결하며 새로운 방법론을 제시한 Scheduled Sampling for Transformers라는 논문이 있었습니다. 이 논문에서 아이디어를 얻어, 이 프로젝트에서는 다양한 Sampling Ratio 별 Scheduled Sampling의 효용성을 세가지 자연어 과제에서 검증해봅니다.
2. Background
- Quadratic Complexity of Attention Mechanism
일반적인 트랜스포머에서 사용하는 어텐션은 Scaled Dot Attention입니다. 이는 간단한 연산으로 뛰어난 성능을 보이지만, 그 연산 복잡도에 있어서는 O2 만큼의 복잡도가 발생합니다. 때문에 입력시퀀스가 길어지는 과제를 해결함에 있어서는 매우 비효율적인 모습이 보입니다.
- Efficient Attention Mechanism
어텐션 연산의 효율성을 향상시키기 위한 다양한 방법이 제시되었습니다. 이 방법들 중 대표적으로는 시퀀스 길이를 특정 길이의 블록으로 분할하여 취합하는 방법과 모든 포인트 참조 연산을 Sparse하게 변환하는 방법이 있습니다. 그러나 어텐션의 강점은 한 번에 모든 포인트에 대한 참조를 수행할 수 있는 능력에 있습니다. 이러한 관점에서 볼 때, 블록 분할 및 Sparse 연산은 어텐션 연산의 강점을 약화시키는 경향이 있습니다. 따라서 이 연구에서는 자르거나 Sparse 연산이 아닌 다른 두 가지 방법론을 채택합니다. 전체 어텐션 매트릭스 중 일부 토큰들 간의 관계만 계산하여 계산 복잡도를 줄이는 방법. Sparse Transformer, Longformer, Big Bird 등 이 방식은 벡터간 유사도를 측정한 결과를 반영하는 것이 아닌, 고정된 패턴을 기반으로 어텐션을 수행하도록 하는 방식입니다.
- Sequence Length Projection
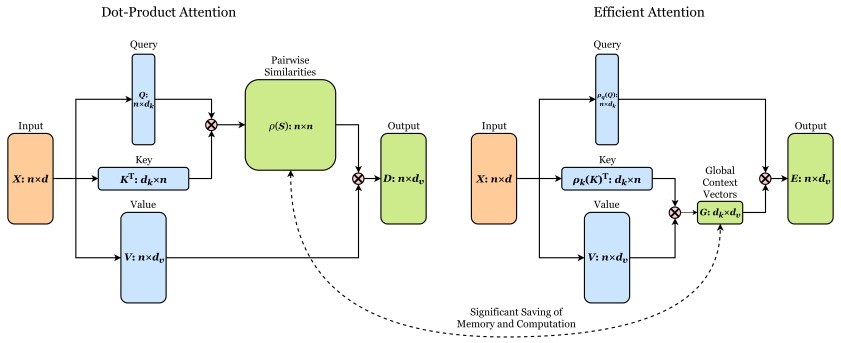
Efficient Attention: Attention with Linear Complexities 논문에서 제시한 Efficient Attention은 기존 Scaled Dot Product Attention의 연산 순서를 변경한 것 만으로 복잡도를 감소시켜, 입력 길이에 대한 컴퓨팅 자원의 과도한 사용을 감소시킨 기법입니다. 어텐션은 기본적으로 두번의 매트릭스 곱 연산을 수행합니다. S = KQt(유사도), D=SV(어텐션 값). 이때 차원의 변환을 살펴보면 ... 이렇게 됩니다. 하지만 Efficient Attention에서는 그 순서를 ~~~하게 변환시켜서 어텐션 계산을 근사화하여 계산 복잡도를 --에서 --로 줄이는 방법. Linformer, Performer, Linear Transformer 등
3. Architecture
- Back Bone Model Architecture
- 전체 실험군 모델의 백본모델 구조는 Standard Transformer와 Evolved Transformer를 사용
- Transformer Variants 프로젝트의 실험 결과를 참조해, 인코더에만 Evolved Transformer의 구조를 차용
- 백본 모델 모두 디코더의 구조는 동이하며, 인코더의 구현 방식에서만 차이를 둠
- Scaled Dot Product Attention을 디폴트 연산으로 사용
- Sequence Length Projection Type
- Sequence Length에 따라 Quadratic하게 증가하는 연산 복잡도의 해소를 위해 Sequence Length의 차원을 저차원으로 사영시킴
- 사영의 방식을 선형 변환과, 비선형 변화 두 가지로 나누어 모델링에 적용
- 기존 Sequence Length에서 0.5배 감소한 차원으로 Projection 적용
- 비선형 변환을 위해 GELU 활성화 함수 활용
- Application of Sequence Length Projection
- SLP는 인코더의 연산 과정서에만 적용
- 인코더의 SLP 적용 방식을 Half와 Full 두 가지로 나누어 모델 구조에 적용
- Full의 경우, 인코더의 모든 레이어에서 동일한 Type의 SLP를 사용. 일관된 구조로 인해 모델 구조가 단순하기에 Type별 특성 파악에 용이
- Half의 경우, 인코더의 저층 레이어에서는 Scaled Dot Product Attention을 사용함으로써 모든 토큰간의 관계성을 포착할 수 있도록 유도함. 그리고 인코더의 상위 레이어에서는 Sequence Length Projection을 사용해 Low Rank에서의 의미를 포착 할 수 있도록 유도
4. Experimental Setup
- Data Setup
- Dataset: CNN Daily Mail
- Tokenizer: BPE Tokenizer
- Vocab Size: 30,000
- Train Data Volumn: 50,000
- Valid Data Volumn: 5,000
- Test Data Volumn: 100
- Model Setup
- Architecture: Standard Transformer & Evolved Transformer
- Input Dim: 30,000
- Output Dim: 30,000
- Embedding Dim: 256
- Hidden Dim: 256
- PFF Dim: 512
- Training Setup
- Num Epochs: 10
- Batch Size: 32
- Learning Rate: 5e-4
- LR Scheduler: ReduceLROnPlateau
- Optimizer: AdamW
- Apply AMP: True
- Gradient Accumulation Steps: 4
- Early Stop Patient: 3
5. Result
- Standard Transformer Based Models
- Evolved Transformer Based Models
- Result Analysis
- SLP 적용 모델들에서 최대 GPU 메모리 사용량과 Epoch Time 모두 감소했습니다. 특히 Full SLP Type 모델에서 이 감소가 더 두드러져, SLP가 메모리 부담을 줄임과 동시에 학습 속도 개선에 효과가 있음을 확인했습니다.
- 평균 GPU 메모리 사용량은 SLP 미적용 모델이 가장 낮다는 결과는 SLP 적용을 위한 부수적 레이어가 모델에 추가됨으로 인해 발생한 결과로 볼 수 있습니다.
- 평균 GPU 메모리 사용량이 소폭 증가한 것에 비해, 최대 메모리 사용량 감소와 시간 단축 측면에서의 개선이 크게 이루어 졌다는 사실에서 긍정적인 Trade-Off가 발생했음을 확인 할 수 있습니다.
- 추가적으로 Epoch 마다의 평균 GPU 메모리 사용량의 증가보다, 최대 메모리 그리고 시간 측면에서의 개선이 훨씬 크게 작용함을 통해 긍정적 방면의 Trade-Off가 발생함을 확인 할 수 있습니다.
- 성능 측면에서는 Evolved Transformer 기반 모델이 Standard Transformer 기반 모델보다 우수했습니다. Standard Transformer 기반 모델들은 SLP Type보다 적용 방식에 더 큰 영향을 받았으며, Evolved Transformer 기반 모델은 SLP Type의 영향을 더 받았습니다.
- Standard Transformer 기반 모델 중에서는 Standard Full Non-Linear Attention Model이 가장 좋은 성능을 보였습니다. 이는 모델의 복잡성이 부족할 때 Full Non-Linear Attention이 이를 보완해준 것으로 해석됩니다.
- 반면, Evolved Transformer 기반 모델에서는 Evolved Half Non-Linear Attention Model이 가장 좋은 성능을 보였습니다. 이는 Evolved Transformer가 복잡한 구조 내에서 기존 어텐션을 기반으로 최적화되어 있어, SLP를 부분적으로 적용하는 방법이 더 효과적이었기 때문으로 볼 수 있습니다.
| Model | Score | Epoch Time | Avg GPU | Max GPU |
|---|---|---|---|---|
| Standard Model | 2.13 | 2m 30s | 0.39GB | 6.82GB |
| Standard Half Linear Attention Model | 2.84 | 2m 20s | 0.40GB | 6.62GB |
| Standard Full Linear Attention Model | 3.50 | 1m 49s | 0.41GB | 6.01GB |
| Standard Half Non-Linear Attention Model | 2.34 | 2m 21s | 0.40GB | 6.63GB |
| Standard Full Non-Linear Attention Model | 3.76 | 1m 51s | 0.41GB | 6.05GB |
| Model | Score | Epoch Time | Avg GPU | Max GPU |
|---|---|---|---|---|
| Evolved Model | 11.47 | 2m 02s | 0.39GB | 5.98GB |
| Evolved Half Linear Attention Model | 10.62 | 1m 51s | 0.40GB | 5.79GB |
| Evolved Full Linear Attention Model | 11.74 | 1m 42s | 0.41GB | 5.59GB |
| Evolved Half Non-Linear Attention Model | 13.51 | 1m 52s | 0.40GB | 5.80GB |
| Evolved Full Non-Linear Attention Model | 12.39 | 1m 42s | 0.41GB | 5.60GB |
6. Conclusion
이번 프로젝트에서는 긴 시퀀스 처리 능력 향상을 위한 Sequence Length Projection(SLP)의 효과를 검증했습니다. 실험 결과, SLP를 적용한 모델들은 최대 GPU 메모리 사용량과 Epoch Time이 모두 감소했습니다. 특히 Full SLP Type 모델에서 이러한 감소가 더 두드러졌습니다. 이는 SLP가 메모리 사용을 줄이고 학습 속도를 향상시키는 데 효과적임을 보여줍니다.
평균 GPU 메모리 사용량은 SLP 미적용 모델이 가장 낮았습니다. 이는 SLP를 적용하면서 추가된 레이어 때문입니다. 그러나 평균 메모리 사용량의 소폭 증가에도 불구하고, 최대 메모리 사용량 감소와 시간 단축 측면에서의 개선이 더 컸습니다. 이는 긍정적인 Trade-Off가 발생했음을 의미합니다. 결과적으로, 평균 GPU 메모리 사용량의 증가보다 최대 메모리 사용량 감소와 시간 단축 측면에서의 개선이 훨씬 크게 작용했습니다.
성능 측면에서 Evolved Transformer 기반 모델은 Standard Transformer 기반 모델보다 뛰어났습니다. Standard Transformer 기반 모델은 SLP Type보다 적용 방식에 더 큰 영향을 받았으며, Evolved Transformer 기반 모델은 SLP Type의 영향을 더 받았습니다. Standard Transformer 모델 중에서는 Standard Full Non-Linear Attention Model이 가장 높은 성능을 보였는데, 이는 이 모델이 복잡성을 잘 보완했기 때문입니다. 반면, Evolved Transformer 모델에서는 Evolved Half Non-Linear Attention Model이 가장 우수했습니다. 이는 Evolved Transformer가 본래 복잡한 구조에 최적화되어 있어, SLP를 부분적으로 적용하는 것이 더 효과적이었기 때문입니다.
종합적으로, SLP는 긴 시퀀스 처리에서 메모리 효율성과 학습 속도를 향상시키는 데 유용하며, 모델의 유형과 구조에 따라 그 효과가 다르게 나타날 수 있음을 확인했습니다.